pub enum Foo {
A(u8),
B(u16),
C(u32),
D(u64),
}

This presents real pain when collecting a large number of them into a Vec or HashMap. The padding can be dealt with using some form of struct of arrays (SoA) transformation that stores the tag in a separate allocation. However, reducing the variant fragmentation is not so trivial.
You could hand-roll specialized data structures for a particular enum that reduce fragmentation to a minimum; but doing this generically for an arbitrary enum with maximum memory efficiency is close to impossible in Rust. The only options we have are proc-macros, which compose poorly (no #[derive] on third-party code or type aliases) and are not type aware (unless using workarounds based on generic_const_expr, which infect the call graph with verbose where-clauses and don't work with generic type parameters). Zig on the other hand let's us perform the wildest data structure transformations in a generic and concise way.
Before I go into the implementation details, I'd like to explain why reducing the aforementioned memory fragmentation is useful in practice.
To me, one of the biggest motivators for efficient enum arrays has been compilers. One problem that keeps coming up when designing an AST is figuring out how to reduce its memory footprint. Big ASTs can incur a hefty performance penalty during compilation, because memory latency and cache evictions are frequent bottlenecks in compiler frontends. Chandler Carruth's video on the Carbon compiler has been making the rounds on language forums. In it he describes how a parsed clang AST regularly consumes 50x more memory than the original source code!
Alright, so what does this have to do with enums? Well, the most common way of representing syntax tree nodes is via some kind of recursive (or recursive-like) data structure. Let's define a node for expressions in Rust, using newtype indices for indirection:
enum Expr {
Unit,
Number,
Binary(Operation, ExprId, ExprId),
Ident(Symbol),
Eval(ExprId, ExprSlice),
BlockExpression(ExprId, StatementSlice)
}
type expr =
| Unit
| Number
| Binary of op * expr * expr
| Ident of symbol
| Eval of expr * stmt list
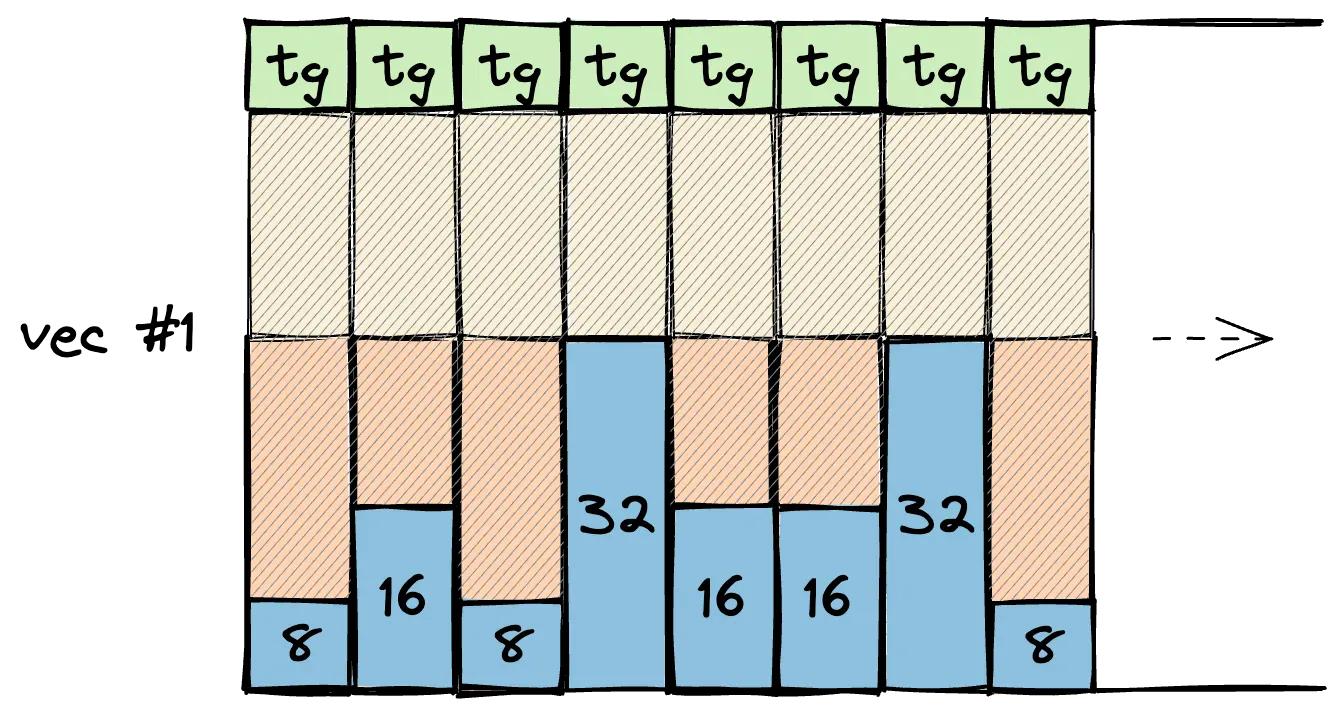
The most common way to improve packing efficiency is by just keeping the enum variants as small as possible using tagged indices (*).
Unfortunately, that doesn't completely solve the fragmentation issue. The other way is to tackle the container type directly! We could use a struct-of-arrays approach to store discriminant and value in two separate allocations. In fact, that's what the self-hosted Zig compiler actually does.
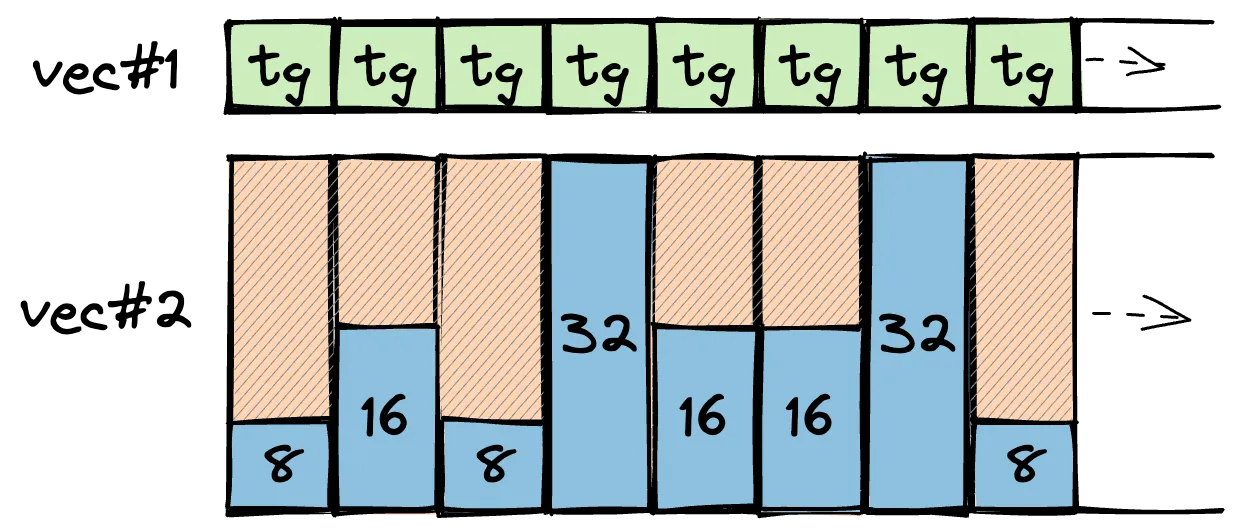
Because of Zig's staged compilation, we can have container types that perform this SoA transformation generically for any type. In Rust, we're constrained to proc-macros like soa_derive which has several downsides (e.g. we can't place #[derive] on third-party types without changing their source).

We could stop here, but let's consider enums that have lots of variants that can be grouped into a small number of clusters with the same type size:
enum Foo {
A(u8, u8),
B(u16),
C(u16),
D([u8; 2]),
E(u32),
F(u16, u16),
G(u32),
H(u32),
I([u8; 4]),
J(u32, u32),
K(u32, (u16, u16)),
L(u64),
M(u64),
N(u32, u16, u16),
O([u8; 8])
}
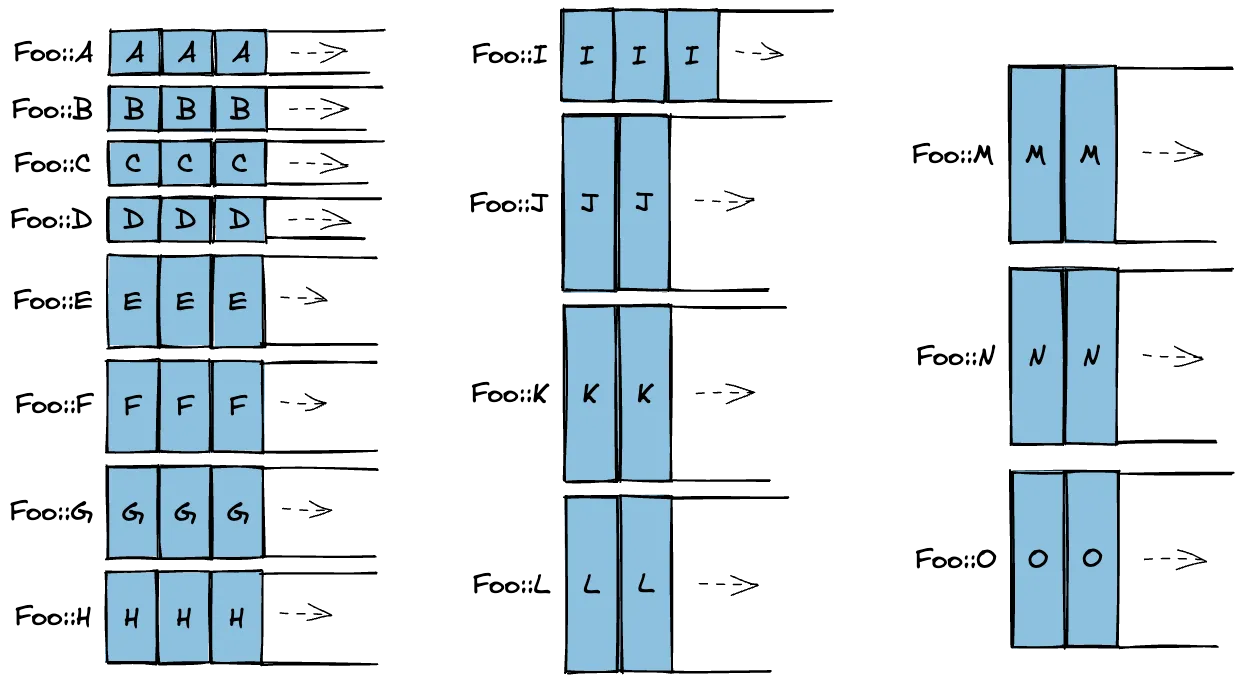
As you can see, the one-vec-per-variant approach would add 15 vectors.
It's likely that the number of (re)allocations and system calls would
increase substantially, and require a lot of memory to amortize
compared to the naive Vec
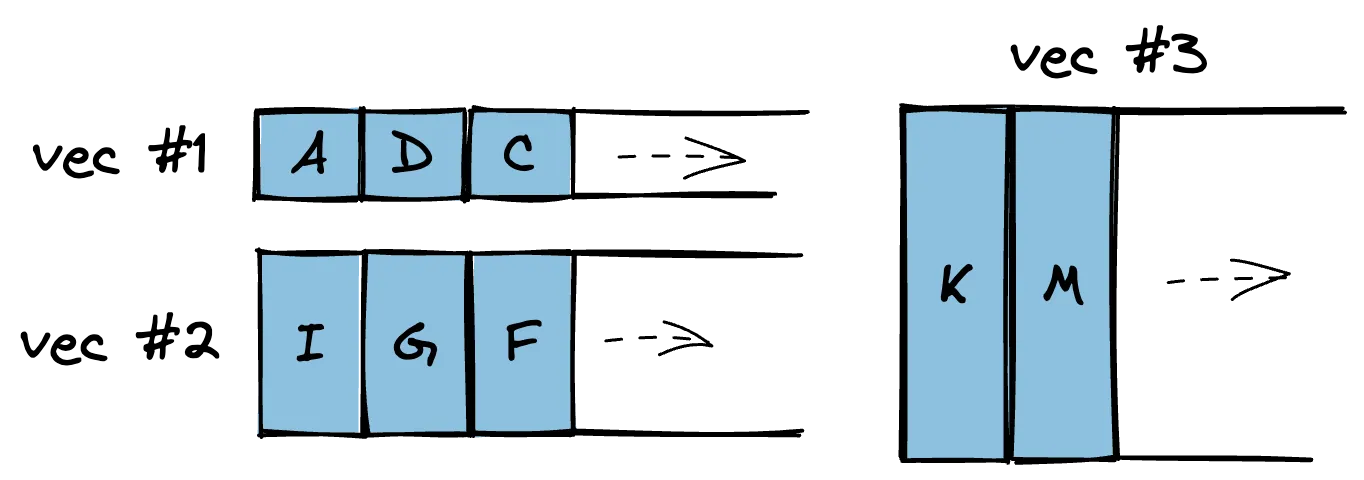
Now, if we group every variant by size, we get three clusters: 2, 4, and 8 bytes. Such clusters can be allocated together into the same vector - thereby reducing the number of total vectors we have in our container by 80%. So we could realistically store variants of Foo in three clusters:
struct FooVec {
c_2: Vec<[u8; 2]>, // A - D
c_4: Vec<[u8; 4]>, // E - I
c_8: Vec<[u8; 8]>, // J - O
}
You could say this is a dense version of our AoVA pattern. However, once we colocate different variants in the same allocation, we lose the ability to iterate through the vector in a type-safe way. The only way to access elements in such a container is via the tagged pointer that was created upon insertion. If your access pattern does not require blind iteration (which can be the case for flattened, index-based tree structures), this might be a worthwhile trade-off.
I've implemented a prototype of this data structure in Zig. The most important pieces are the compiler built-ins that allow reflection on field types, byte and bit sizes, as well as inspecting the discriminant.
// determine kind of type (i.e. struct, union, etc.)
switch (@typeInfo(inner)) {
.Union => |u| {
// store mapping from union field -> cluster index
var field_map = [_]u8{0} ** u.fields.len;
// iterate over union fields
for (u.fields, 0..) |field, idx| {
// compute size
const space = @max(field.alignment, @sizeOf(field.type));
// insert into hashtable
if (!svec.contains_slow(space)) {
svec.push(space) catch @compileError(ERR_01);
}
field_map[idx] = svec.len - 1;
}
// return clusters
return .{ .field_map = field_map, .sizes = svec };
},
else => @compileError("only unions allowed"),
}
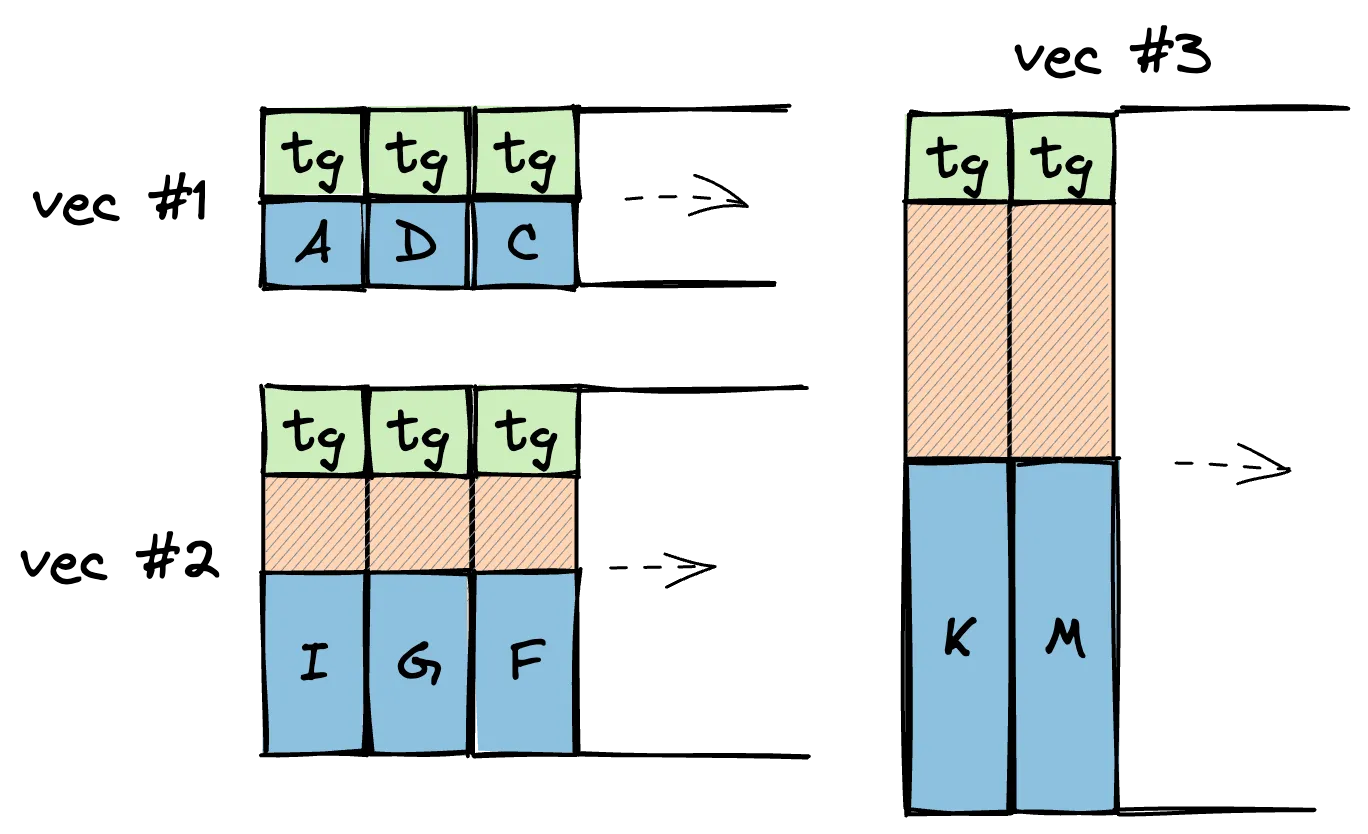
If you do want type-safe iteration, you could pay the cost of padding, and add the tag back in:
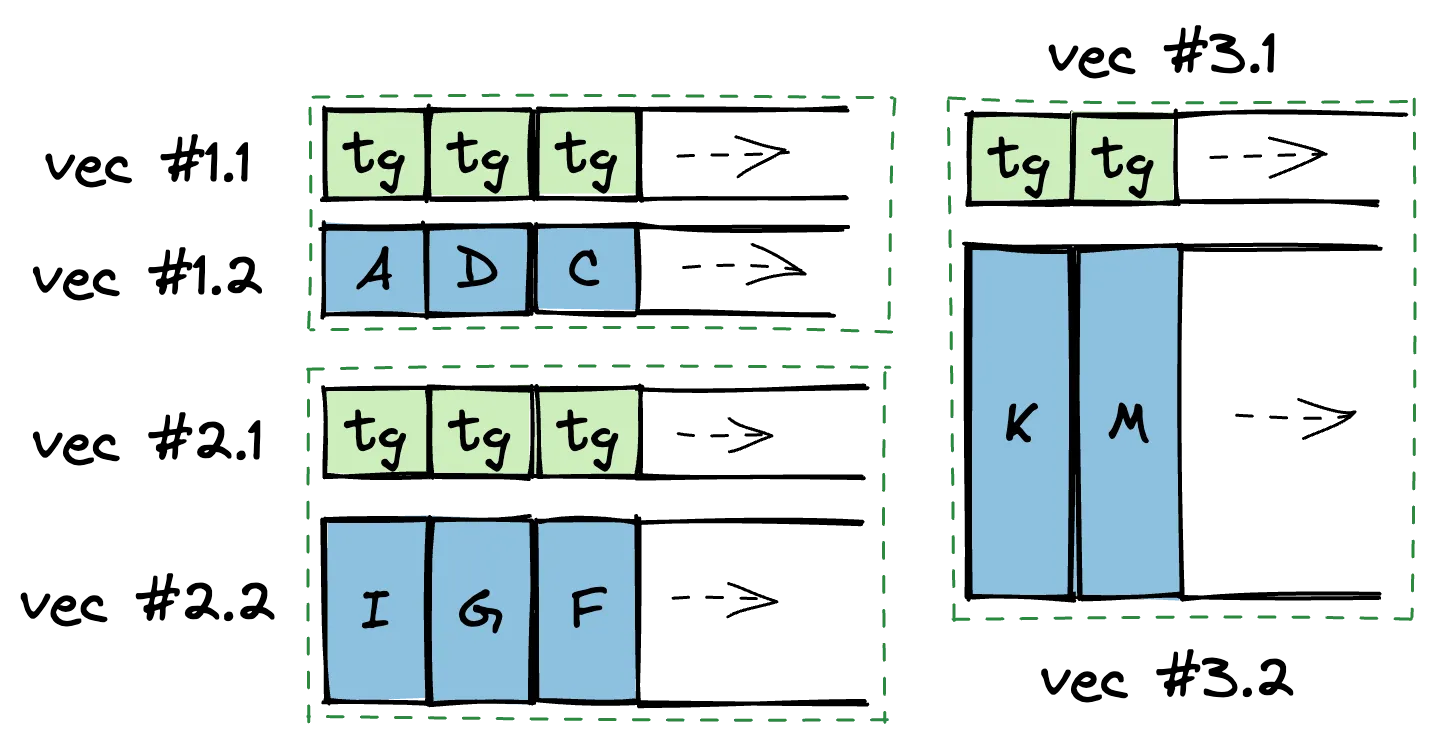
If the padding is too much, you can do an SoA transformation on each of the variant arrays.
So as you can see, there's quite a few trade-offs we can make in this space - and they all depend on the concrete memory layout of our enum.
While creating such data structures is pretty straightforward in Zig, creating any of these examples in Rust using proc macros is basically impossible - the reason being that proc macros don't have access to type information like size or alignment. While you could have a proc macro generate a const fn that computes the clusters for a particular enum, this function cannot be used to specify the length of an array for a generic type.
Another limit to Rust's generics is that the implementation of a generic container cannot be conditioned on whether the given type is an enum or a struct. In Zig, we can effectively do something like this:
// this is pseudocode
struct EfficientContainer<T> {
if(T.isEnum()) {
x: EfficientEnumArray<T>,
} else {
x: EfficientStructArray<T>,
}
}
We can also specialize the flavor of our AoVA implementation based on the enum. Maybe the benefits of colocating different variants only starts to make sense if we reduce the number of vectors by more than 90%.
So ultimately we gain a lot of fine-grained control over data structure selection. And if we have good heuristics, we can let the type-aware staging mechanism select the best implementation for us. To me, this represents a huge step in composability for high-performance systems software.
While implementing my prototype, I noticed other ways of saving memory. For instance, if you know the maximum capacity of your data structure at compile time, you can pass that information to the type-constructing function and let it determine the bitwidth of the returned tagged index.
When this tagged index is included in a subsequent data structure, let's say another enum, this information carries over naturally, and the bits that we didn't need can be used for the discriminant!
So what Zig gives you is composable memory efficiency. By being specific about the number of bits you need, different parts of the code can take advantage of that. And with implicit widening integer coercion, dealing with APIs of different bitwidths stays ergonomic. In a way, this reminds me a lot of refinement typing and ranged integers, so this ties in a lot with my post on custom bitwidth integers.