Before we start: by "custom-width integer types" I'm referring to a language feature that lets users specify integer types with any fixed number of bits (e.g. u7, u12) - instead of being provided a handful of integers that correspond to common xword sizes (e.g. u8,u16, u32,u64). The first time I've encountered this idea was in the Zig language, although it also exists in Clang & LLVM IR.
Now, Zig is an odd one. The language was founded on pure systems programming pragmatism - an antithesis of ivory-tower category theory shenanigans, and a place where Curry is just an earthy Indian spice. But time and time again, through pragmatic, real-world justifications, we witness a collision of these two worlds.
How come? It turns out that accurately modeling your program's intended behavior is in everyone's best interest. As long as this model is programatically enforced (e.g. by language semantics), we can get two big benefits: (1) we improve correctness and safety of our programs and (2) we open the door for aggressive compiler optimizations. And custom-width integer types are a perfect example of this.
type u7 is range 0..127;
subtype u7 is Integer is range 0..127;
pub fn foo(x: u10) u10 { return x; }
pub fn main() !void {
var y: u9 = 0;
_ = square(y);
}
note: unsigned 8-bit int cannot represent all possible unsigned 9-bit values
pub struct EvenU64(u64);
impl EvenU64 {
pub fn new(i: u64) -> Result<Self, Error> {
match i % 2 == 0 {
true => Ok(Self(i)),
_ => Err(Error::InvalidArgument),
}
}
}
You can find other useful examples in Rust's standard library. For this to work, your language of choice needs something akin to access modifiers (Java, C#, C++, Rust) or modules (ML-family), that allow you to restrict construction and modification of objects. Ironically this is not possible in Zig, because the language does not have a notion of private or immutable fields.
However, the encapsulation approach is still only an emulation of refinement, due to the lack of automatic subtyping. Let's instead take a look at languages that have first-class support for refinement types.
let pos = x:int { x > 0 } //the positive numbers
let neg = x:int { x < 0 } //the negative numbers
let even = x:int { x % 2 = 0 } //the even numbers
let odd = x:int { x % 2 = 1 } //the odd numbers
forall and exists; once you allow
existential or universal quantification, you're in the world
of dependent types, which require formal proof terms.
The idea is that we constrain the type to values for which the
predicate on the right evaluates to true. Another great example
of a language with first-class refinement types is
LiquidHaskell:
{-@ type Nat = {v:Int | 0 <= v} @-}
{-@ type Even = {v:Int | v mod 2 == 0 } @-}
{-@ type Lt100 = {v:Int | v < 100} @-}
{-@ abs :: Int -> Nat @-}
abs :: Int -> Int
abs n
| 0 < n = n
| otherwise = 0 - n
When writing performance-critical data structures, every bit of memory footprint counts. Especially for concurrent data structures, our critical bottlenecks often happen to be concentrated on a small number of integers (e.g. indices, RCU pointers, DCAS timestamps, hash keys, bitmaps, tails & heads, metadata, semaphores, etc...).
Let's take pointer compression for example. It's an optimization most often used for making buffer indices so small that they can (1) fit into fewer cache lines to improve locality and read latency or (2) can be read, modified and updated in large batches, especially for SIMD or atomic stores.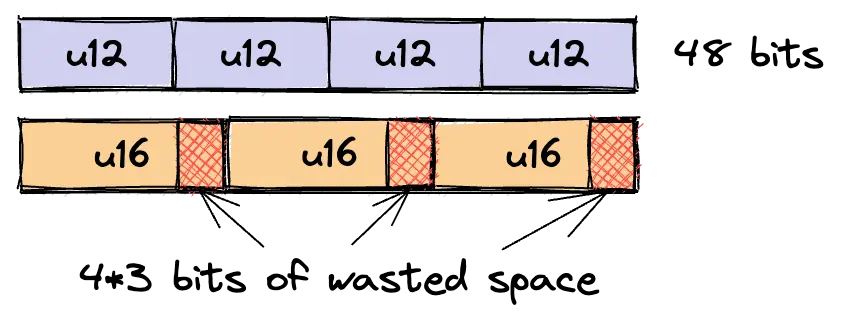
Note: Instead of shift + mask, you can use BEXTR on x86, which is part of the BMI1 extension (post-Haswell). The equivalent on ARMv6+ is UBFX and on PowerPC you have rlwinm.

Another example that often comes up in this context is union types (especially tagged unions). Even small size discrepancy between union variants can drastically increase our memory consumption. This is often an issue when dealing with recursive data structures like ASTs.
Example: I'm parsing a flattened AST and want to add a new node type for block expressions. A block always ends with another expression, but may optionally have a certain number of statements preceding it. Let's take a shot at it with some pseudocode:pub enum Expr {
BlockExpr(u32, Option<u32>, u8)
// ^^^ ^^^ ^^
// expr pointer | |
// statement pointer |
// statement count
}
The first field is an index into our array of expressions, and the two remaining fields are essentially a fat pointer. That's 10 bytes for unaligned enum values and 16 with padding! The statement pointer seems wastefully large, but 16-bits (~65k statements) is definitely too low. How about u21? That will give us a budget of 2 million total addressable statements, which seems good. Now we have a budget of u10 for the statement count (max of 1024 statements per block seems reasonable) and can use the most-significant bit for the Option discriminant.
We can also think about the number of variants in the Expr enum. It's common to have a few dozen different expression types, so we need some bits for the enum tag. We can take them from the expression pointer*.pub enum Expr {
BlockExpr(u24, Option<u21>, u10)
}
This idea only works if our compiler understands that the MSBs can be safely used for the discriminant. In languages like Rust, you can add custom-width integers inside of enums with heavy use of proc macros and unsafe transmutes. But once your variant tuples contain newtypes, the size information is lifted to the semantic level, at which point this hack becomes impossible(*). (*): An exception to this is the Rust compiler. If you take a look at its source code, you'll quickly find many instances of special unstable compiler hacks that are used to squeeze out performance or memory-efficiency.
With these few changes we've just shaved off two bytes, while still having 2-4 bits to spare for metadata, depending on the number of variants. And since the whole thing fits into 8 bytes, we basically get alignment for free. Without native support for custom-width integers, creating these oddly sized nested enums would become a real chore.Shaving off unneeded bits isn't only relevant for software. Most x86_64 machines today can only use the lower 48-52 bits for physical addressing, which I believe is done for space and efficiency reasons. This leads us directly to the other end of the spectrum, namely hardware design.
In 2020, Erich Keane submitted a patch to LLVM implementing custom-width integers and wrote a great follow-up post about it. The main motivation was to enable more efficient high-level synthesis (HLS) of C and C++ programs. The post is absolutely worth a read, and also mentions some of the intricacies around integer promotion.It's my belief that exactly this shared experience made people from different backgrounds come to the same realization. It's no surprise that whenever we are given the ability to convey more information about our problem, we're often rewarded by the compiler with correctness, consistency and performance. I'm looking forward to more languages beyond Zig adopting this feature in the future.