- To make it easy to create a lexer, so you can focus on more complex problems.
- To make the generated lexer faster than anything you'd write by hand.
I had my doubts about the second part. I was aware of the efficiency of state machine driven lexers, but most generators have one problem: they can't be arbitrarily generic and consistently optimal at the same time. There will always be some assumptions about your data that are either impossible to express, or outside the scope of the generator's optimizations. Either way, I was curious to find out how my hand-rolled implementation would fare.
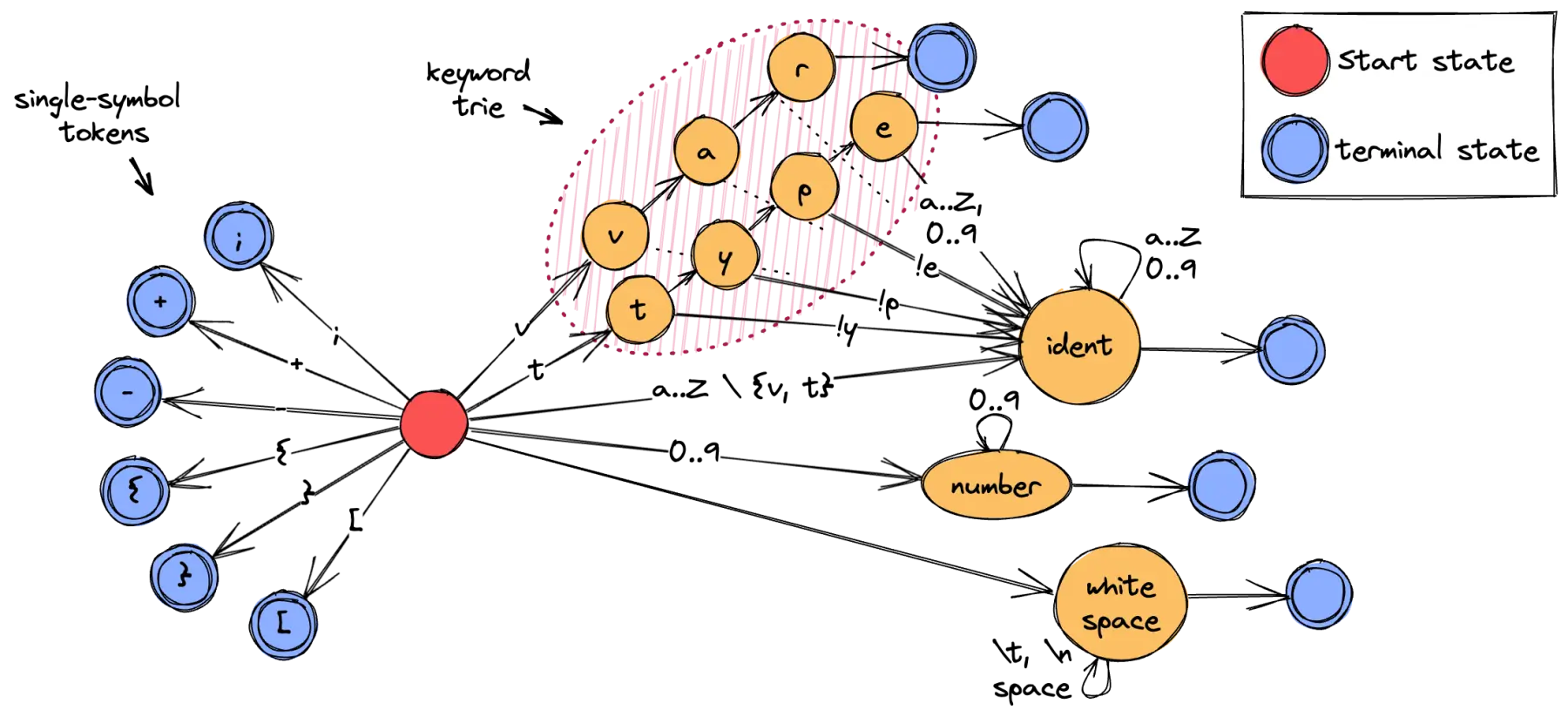
Each invocation of next_token() begins at the start state, continually performing state transitions by looking up the next character, until we hit a terminal state. The terminal state contains the information about the token variant. If the number of language keywords is sufficiently small, we could even build a trie for matching against a static set of keywords.
The implementation of the state lookup is input-dependent. For ASCII input, we can let each state define a full jump table for every possible character, and use the raw bytes as lookup indices into the state transition matrix. To handle full UTF-8 input, we might dispatch to a more costly, branchy function with a straightforward switch statement.
For more resources, this article by Sean Barret gives a good overview of implementing a table-driven lexer in C, and ways to improve performance via e.g. equivalence classes. I also recommend a blog post on stacking lookup tables by Maciej Hirsz, the author of logos.
Since I'm working on a compiler in my free time, I already have a basic lexer available. Lexing usually takes up the least amount of time in modern compilers, so I prioritized simplicity over performance in my implementation. One exception to this is keyword matching, for which I used a perfect hash function.
Note: Compiler bottlenecks are pretty varied. For monomorphizing compilers that emit native binaries, the bottleneck is more often in the optimizer and codegen stage. I've uploaded some Rust compiler timings for the regex crate As expected, the frontend is pretty lightweight, and significant time is spent on the optimization passes, as well as generating the LLVM IR and native code. But that is not always the case!Still, it would be interesting to see by how much logos outperforms my naive implementation. The target file was 100KB of pseudocode (around ~8k LoC) and I ran the test on an Apple M1 system:
lnpl: 312,837 ns/iter (+/- 4,952)
logos: 174,476 ns/iter (+/- 3,062)
Credit where credit is due, that is a pretty big performance difference! Logos chews through the file in 174us - almost twice as fast as our naive implementation. However, things are different on x86_64:
lnpl: 201,148 ns/iter (+/- 27,477)
logos: 221,110 ns/iter (+/- 36,000)
My first guess is that this is caused by differences in the speculative execution architecture. If you compare perf reports of both lexers, you can see drastic differences in IPC and branch counts. Note: This discrepancy between control-flow vs. data-dependency was discussed in a recent HN post on branchless binary search. One thing I learned about speculative execution is that it can act as a more aggressive prefetcher - which becomes important when you're dealing with working set sizes beyond L1 or L2. Branchless code often trades control-flow for data dependencies, but most CPUs will not speculate on data for security reasons. Other than that, the main contributor to our implementation's performance is the perfect hash function, which we'll discuss next.
Let's take a look at the list of keywords we are currently matching against:
pub enum Keyword {
Class, For, Fn, Let, Match,
Struct, Ln, While,
}
One of the reasons our naive implementation can already beat logos is that I can exploit the fact that all keywords are less than 8 bytes long - so each keyword fits into a single 64-bit register. That means that keyword comparisons can be done with a single cmp instruction. Note: No need for transmutes here. Comparing appropriately-sized byte arrays are a zero-cost abstraction when compiled with --release. For example, comparing two [u8; 8] on x86_64 yields cmp rdi, rsi; sete al.
To avoid comparing against all keywords, it's pretty common to statically generate a perfect hash function. You can do this with GNU's gperf or just experiment with it on your own. Ideally, such a hash function has a super shallow data dependency tree and makes use of simple instructions (*). (*): Wojciech Mula wrote an article about an efficient perfect hash implementation based on bit extract instructions (e.g. pext on x86, but similar ones exist on other architectures). Examples of parsers that make use of this include Google's V8 and PostgreSQL. However, being faster only on x86 is not enough - we also need to beat logos on ARM. This is why the following benchmarks and tests will all target my Apple M1.
Just out of curiosity: what happens when I place #[inline(always)] on every function?
lnpl: 240,993 ns/iter (+/- 3,382)
logos: 174,476 ns/iter (+/- 3,062)
We seem to get a 30% speedup. I also noticed some API differences between my lexer and logos: my lexer is by default "peekable", so every invocation of next_token contains a branch like this:
pub fn next_token(&mut self) -> Option<&Token<'a>> {
if self.peeked.is_some() {
self.current = self.peeked.clone();
self.peeked = None;
return self.current.as_ref();
}
// [...]
}
Also, my token definition contains a slice:
#[derive(Debug, Clone)]
pub struct Token<'a> {
pub text: &'a [u8],
pub kind: TokenKind,
}
Having a fat pointer + enum, which is wrapped by an Option is most definitely not memory-efficient. After removing peeking logic, the text field, and switching from returning refs to cloning, we're only 25% slower than logos:
lnpl: 220,825 ns/iter (+/- 947)
logos: 174,476 ns/iter (+/- 3,062)
It's nothing to scoff at, but we probably need a more structured approach to improving performance :)
We can also exploit the fact that most of our source code is actually ASCII. Note that this is pretty common for source code (except for APL). I ran a test script on a variety of codebases, and the results are pretty conclusive:
| Repo | Lang | LoC (incl. comments) | ASCII% |
|---|---|---|---|
| Linux | C | 22 million | 99.999% |
| K8s | Go | 5.2 million | 99.991% |
| Apache Spark | Scala | 1.2 million | 99.998% |
| Hubris | Rust | 114k | 99.936% |
We can do an optimization which resembles what compilers do to vectorize loops. In order to unroll a loop n times, we need to check if we can perform n iterations of work at the start of the loop. Depending on this check, we jump to either the scalar or the vectorized implementation (this is called dispatch). If we do this for ASCII, we get:
if !c.is_ascii() {
return todo!("slow implementation");
}
/* rest of the code */
After the if-statement, the compiler can safely assume that c is no larger than a single byte. This gives us pretty competitive results:
lnpl: 206,928 ns/iter (+/- 2,724)
However, todo! terminates the program, which may affect downstream optimizations. And indeed, if we replace the panic with a proper function, we get a regression even with #[inline(never)].
lnpl: 243,292 ns/iter (+/- 7,678)
So while it can bring benefits to dispatch on events with extreme probabilities, we have to do it in a way that plays nicely with automatic vectorization; or we can avoid the dance with the compiler and do it ourselves.
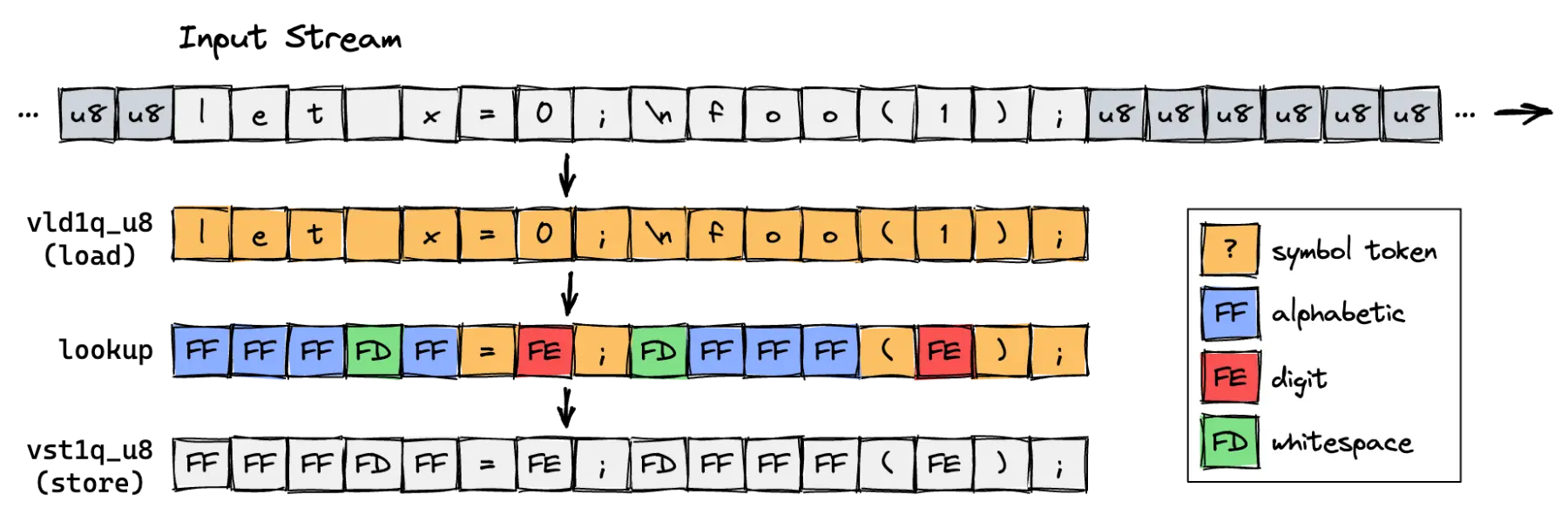
let f(x) =
| x is digit -> 0xfe
| x is whitespace -> 0xfd
| x is alphabetic -> 0xff
| _ -> x
Tokenizing single-symbol tokens (like +, -, *, /, :) is basically free, because we define the enum tag to be identical to its corresponding ASCII code.
Alphanumeric and whitespace characters are the main problem, because their associated tokens (identifiers, numbers and whitespace) can be arbitrarily long.
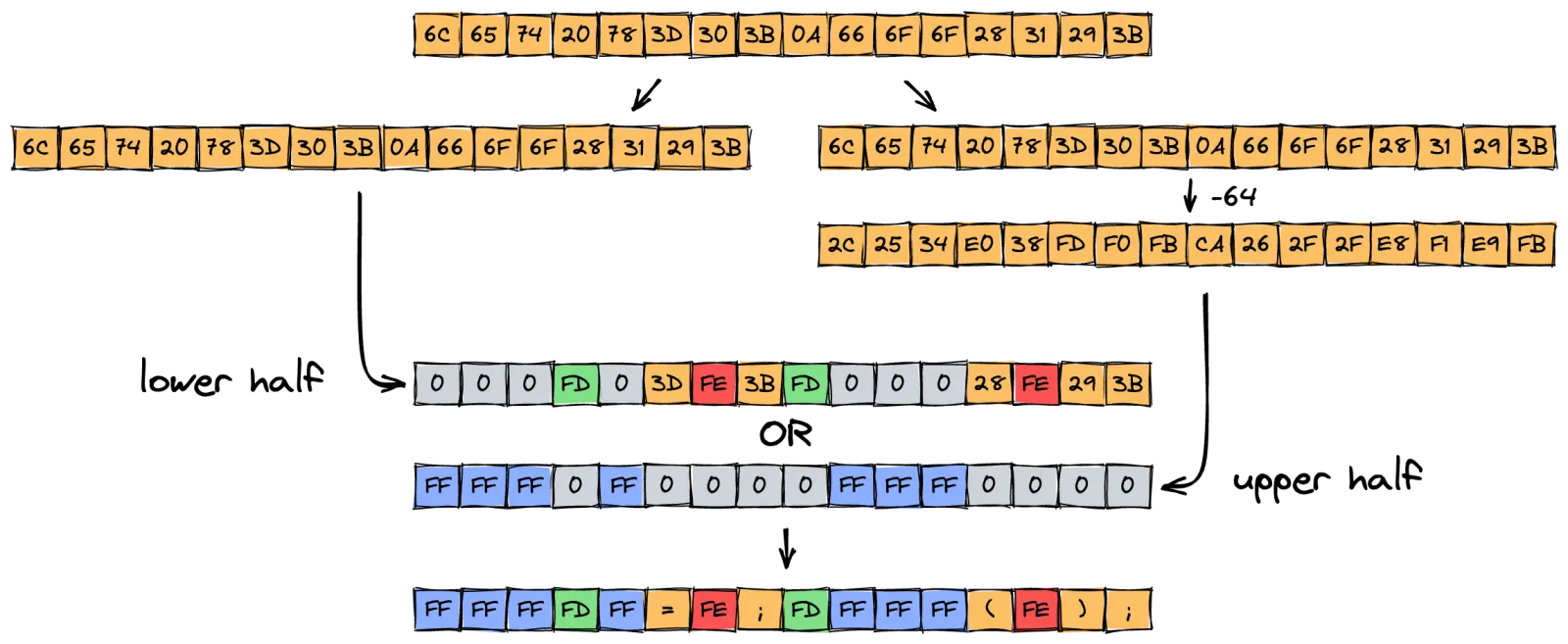
Regarding the lookup: unfortunately, the instruction vqtbl4q_u8 can only index into tables with a maximum size of 64 bytes. To translate the entire ASCII space, we need to map the upper and lower half of the ASCII space in two steps with two seperate tables, and then OR the results.
Once we have the fully mapped representation, we can execute what I call the "skip loop". When we come across an alphabetic character (FF), we know that this is the start of an identifier token. We must then skip over all following alphanumeric characters until we hit the end of the identifier. This boils down to a very simple and shallow state machine:
let initial = buffer[simd_idx];
increment_simd_idx(1)?;
loop {
let combined = (initial << 8) | buffer[simd_idx];
let skip_cond = combined == 0xff_ff
|| combined == 0xff_fe
|| combined == 0xfe_fe
|| combined == 0xfd_fd;
if !skip_cond {
break;
}
increment_simd_idx(1)?;
}
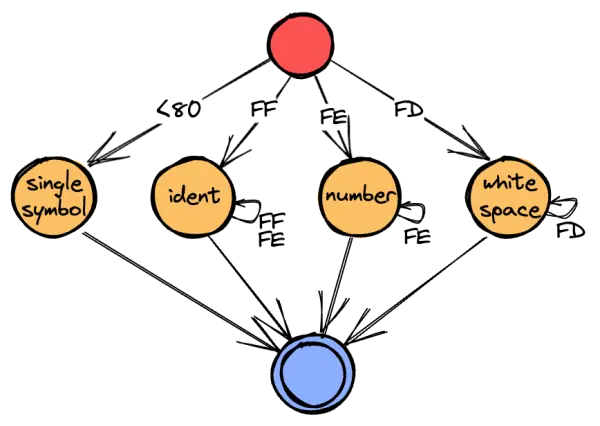
As you can see, the transitions are a lot less complicated, because we collapsed multiple range checks (e.g. "is x alphabetic?") into a single branch (x == 0xff). So while we're still performing state machine looping over characters, we have effectively substituted the data dependency of the jump table approach with a control dependency (*).
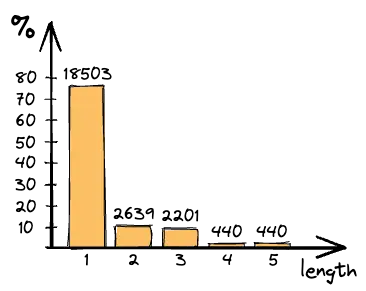
(*): That got me curious: how predictable are our multi-character tokens? Above a histogram of whitespace tokens, categorized by their length. (Whitespace is the most frequently occuring token)
It looks like the skip-loop branch is very predictable for whitespace tokens. For identifiers, I'd need to lex some real-world code, but identifiers generally have a much longer mean *and* tail. So while the MIX of whitespace and identifiers in a character stream might be less predictable, the individual classes most definitely are.
One potential problem with data dependencies, and really with a lot of branchless algorithms, is that they may reveal performance problems in the face of modern speculative execution (e.g. due to not maxing out memory bandwidth or not benefiting from branch prediction). We can run the benchmark again on our current implementation:
logos: 118,476 ns/iter (+/- 322)
Our results are decent, getting a consistent speedup of 35% over logos (for reproduction, see 4a9a1cd).
Next, I revisited the keyword matching function looking for some low-hanging fruits. I tried replacing my whacky multiply + add function with bit extract instructions (in the spirit of pext), but that didn't seem to have any effect.
So I had a look at what we do before we push our bytes into the hash function. To construct the 64-bit register that holds our data, we first load the input characters into a register and then zero out the irrelevant bytes. For instance, the keyword let is three bytes long, so we zero out the other five. This is done with a mask:
let candidate = bytes & ((1 << len) - 1)
This idiom is actually recognized by most optimizing compilers, and replaced with the bzhi instruction on x86 (assuming support for BMI2) and lsl + bic on ARM. But I was curious: what if we instead perform a lookup into a table of precomputed masks?
static bitmasks: [u64; 8] = [
0x0000000000000000,
0x00000000000000ff,
0x000000000000ffff,
0x0000000000ffffff,
0x00000000ffffffff,
0x000000ffffffffff,
0x0000ffffffffffff,
0x00ffffffffffffff,
];
// [...]
let candidate = candidate & bitmasks[len];
To my surprise, the lookup table is actually faster! I didn't measure this in detail, but it seemed to speed up keyword matching by 5-10%. This turned out to not matter much, because keywords are not as frequent in real-world data, but it's an interesting observation nevertheless.
With our implementation reaching an acceptable level of performance, we can try to make our benchmarking data more realistic. To do that, I took two snippets from Oxide's Hubris kernel and removed a few unsupported characters. The result: smaller number of multi-sequence tokens, but identifiers and whitespaces are longer. On top of that, we now allow underscores anywhere inside the identifier. All these things negatively affect our relative improvement over logos:
lnpl: 89,151 ns/iter (+/- 1,048)
logos: 108,257 ns/iter (+/- 1,898)
I believe the main reason for this change is the fact that the branch that recognizes single-character tokens has become less predictable. Another reason is the much smaller number of keywords in our sample, decreasing the benefit of perfect hash keyword matching. Finally, in order to support identifiers with underscores, we needed to complicate our skip loop.
Running benchmarks on file sizes of 5KB, 10KB, 50KB, 100KB and 1MB shows a speedup between 20%-30%. You can try out the final version for yourself (aarch64 only, run cargo bench).
Credit: Thanks to Mahmoud Mazouz for uncovering a performance regression while trying to reproduce the benchmark. The primary culprit was the #[no_mangle] attribute on the next_token function, which I left in the code for debugging convenience.