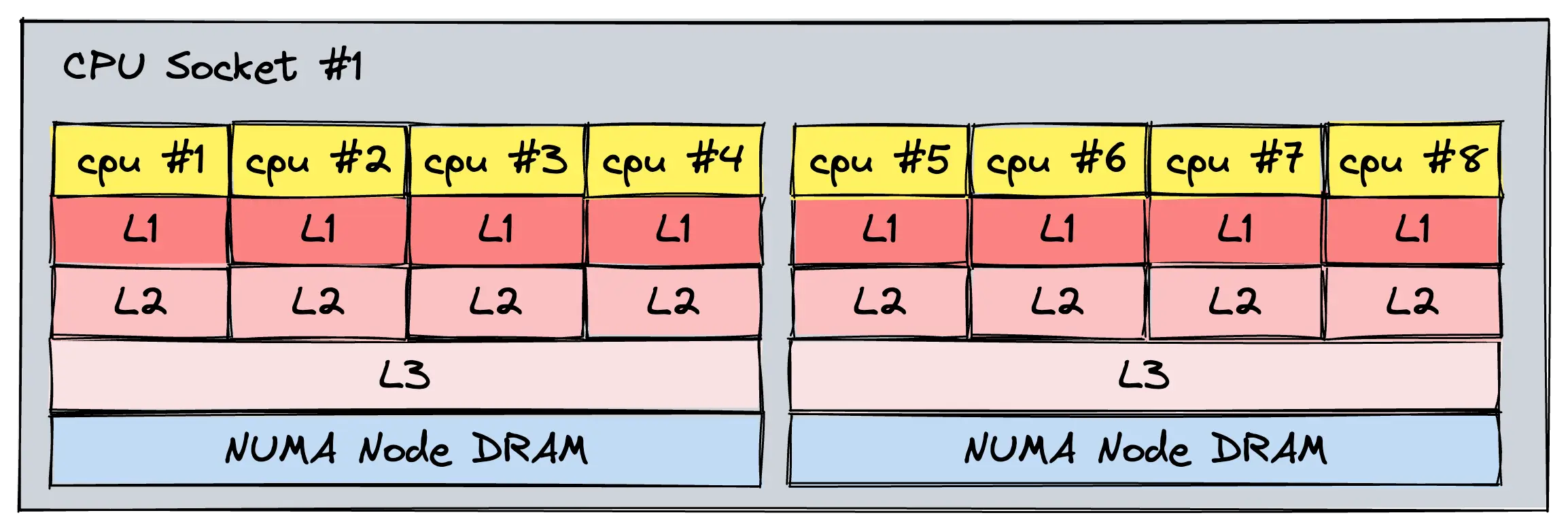
Without some global ordering guarantees, writing meaningful concurrent algorithms becomes pretty much impossible. To resolve this, CPUs employ a microarchitectural cache coherence protocol that (1) propagates writes to all other processors and (2) serializes writes to the same memory location, so that they are observed in the same global order by every processor.
Note: Cache coherency is part of a CPUs memory model and always architecture or ISA specific. Furthermore, operating systems and programming languages may define their own memory models to abstract over a variety of hardware. The C/C++11 memory ordering specification is one such example.Most CPUs follow an invalidation-based protocol like MESI, usually equipped with an additional state for making certain operations more efficient via cache-to-cache transfers. For these protocols, writing to an address generally invalidates all other processors' cache lines that contained this addresses value, thereby forcing the affected processors to pull the latest value from a lower memory level (last-level cache or main memory) on the next read in the worst case. This can strongly degrade performance, and can cause a poorly-implemented multithreaded system to perform worse than its single-threaded counterpart. For a real example, refer to chapter 7.3 of the AMD64 architecture manual, which covers their MOESDIF (Modified, Owned, Exclusive, Shared, Dirty, Invalid, Forward) cache coherence protocol.
Update: As noted by David Chisnall, if the writing processor did not perform a previous load on a cache line, cache coherency protocols may sometimes employ remote stores instead of invalidation. This means that the value is sent to the remote processor over the interconnect, updating the value in-place.Intuitively, it makes sense that lots of processors reading and writing concurrently to the same address would cause a performance bottleneck. This problem is known as true sharing, and is quite easy to identify. False sharing on the other hand is more insidious. It's a type of performance degradation where multiple processors write to different memory addresses concurrently, but still cause lots of cache coherency traffic. How is that possible if they are writing to different memory addresses?
The reason is that the cache coherence protocol is rough-grained and invalidates an entire cache line on any write, so that updating 8 bytes of data (size of an unsigned 64-bit integer) also invalidates 56 neighboring bytes.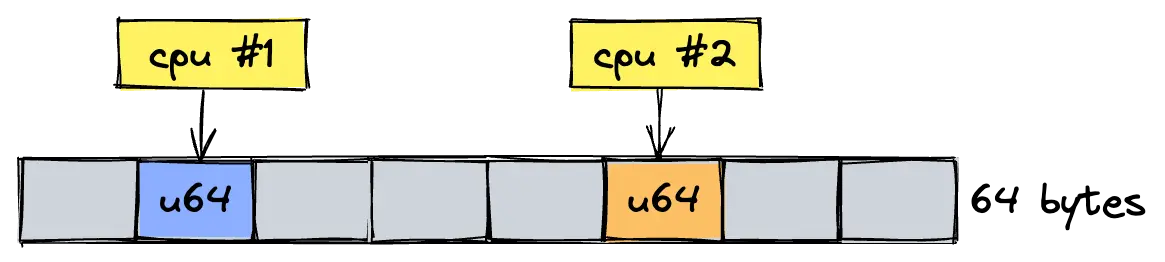
So even though 2 distinct objects are updated by two different processors, we see a similar level of performance degradation as with true sharing, as long as these objects map to the same cache line.
The most egregious offenders are densely packed structs, with each variable being accessed by another thread. This gives you a false illusion of data independence and parallelism.#[repr(C)]
pub struct State {
t1: u64, // only accessed by thread #1
t2: u64, // only accessed by thread #2
t3: u64, // only accessed by thread #3
}
Depending on the alignment of State, all three values will likely map to the same cache line. To avoid this, you generally align variables to a cache line using either macros or padding fields*. (*): Padding fields like this is very common in multithreading libraries or kernel code. In the Linux kernel for example, this is done with the macro __cacheline_aligned_in_smp. You can see it used for the struct bpf_ringbuf in /bpf/ringbuf.c.
By now it's pretty clear that we should definitely avoid false sharing; all that's left is measuring the actual performance gain of cache line alignment.To measure the impact of false sharing, we will perform experiments on a wait-free, bounded, multi-producer single-consumer queue. It's a data structure that allows multiple concurrent threads to push data into a single data stream, which can be read by a consumer thread. The way these concurrent write operations are merged into a single consumable stream differs between implementations.
In our case, producers are pushing data into their own thread-local FIFO ring buffer, which is regularly polled and emptied by the consumer thread. When the queue is full, new data from producers are discarded (partial write / fail on overflow according to this classification).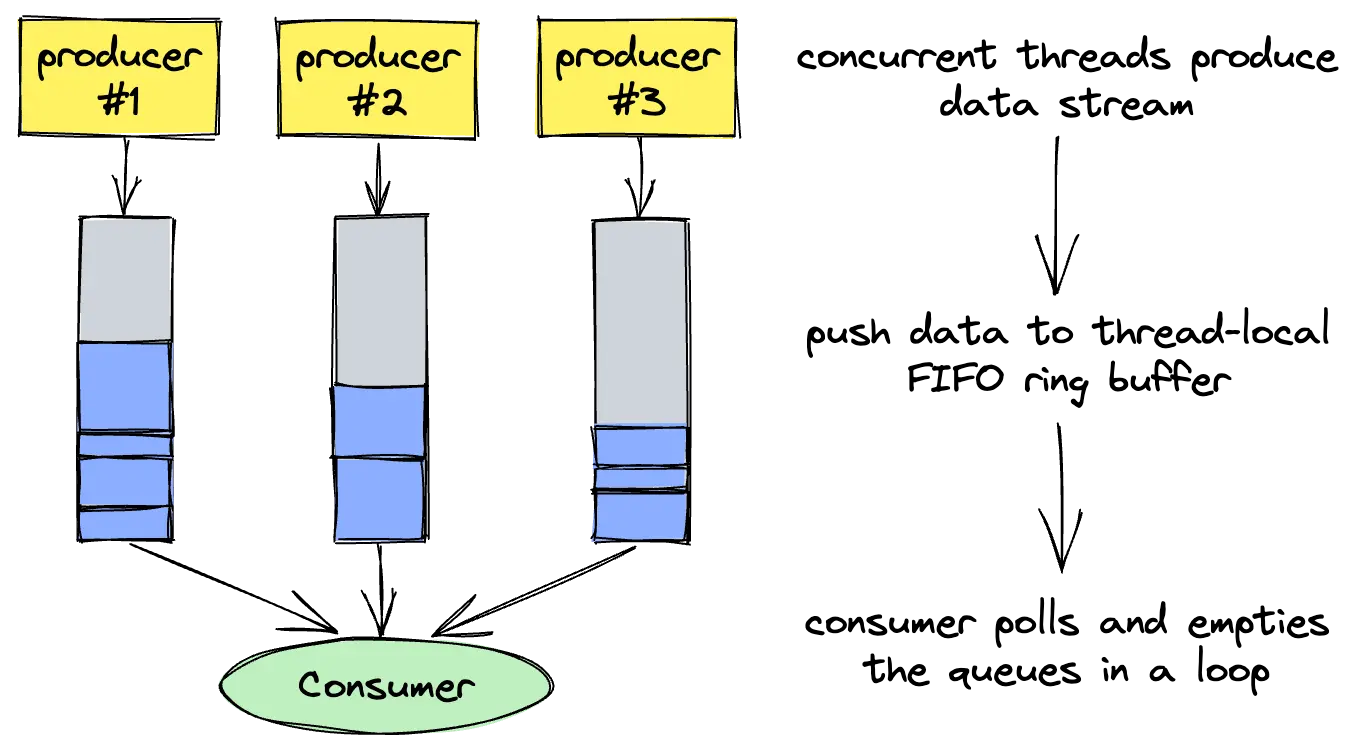
Now the memory layout. The data structure consists of (1) an array of thread-local buffers, represented as a single contiguous backing array and (2) an offset table that stores head and tail offsets of each individual queue. For the purposes of this blog post, the offset table is our main concern. Because whenever producers OR consumer push or pop data off these queues, they perform atomic load/store operations with release/acquire semantics on what are essentially pointers.
The producer p is the only thread that is allowed to modify the p-th head offset, using the push operation. Similarly, the consumer has exclusive write permission for any tail via pop. This means we have no competing store operations (and thus no atomic RMW sequences like compare-and-swap or LL/SC). Great! Except, as we've seen before, independent store operations may still degrade performance due to false sharing.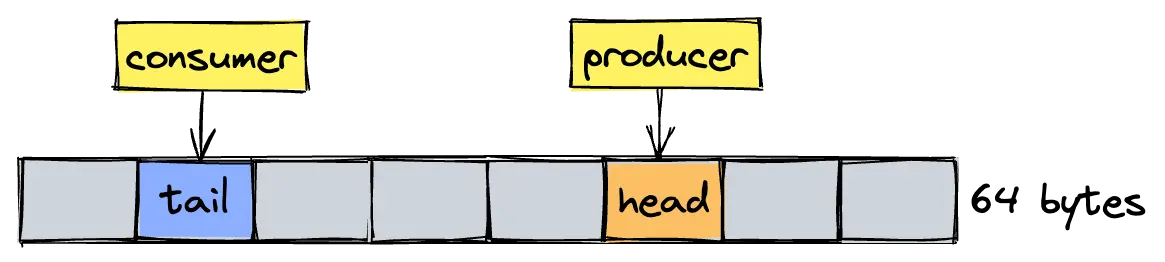
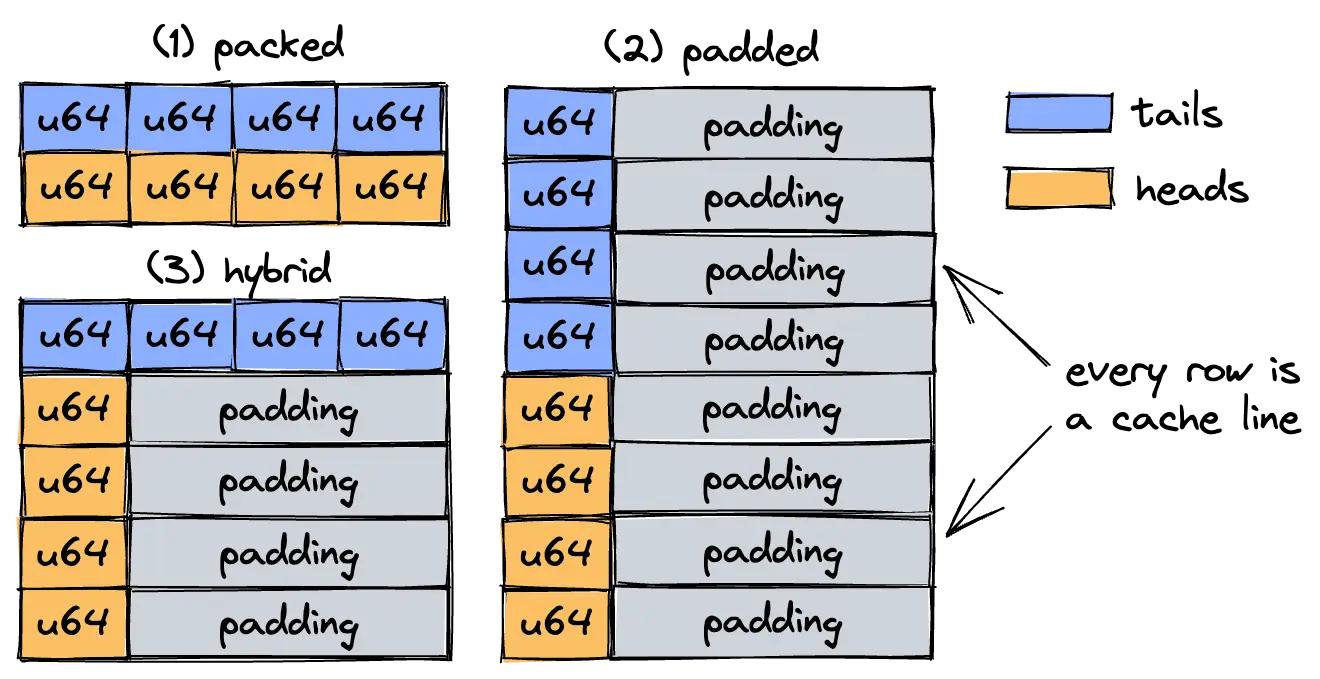
- p: number of producers, depending on CPU
- d: number of dummy instructions inserted between queue ops, values = [0, 500]
- Apple M1 Pro, 10 cores, bare-metal, macOS
- Intel i5-9600k, 4 cores, bare-metal, Windows
- AMD EPYC, 30 cores, KVM, Linux
- Intel Cascade Lake, 30 cores, KVM, Linux [lscpu dump]
The code is written in Rust, and uses the criterion microbenchmarking framework. You can find the code and instructions to run the benchmark here at commit 3fcbe5ed2b (details are in BENCH.md, Linux-only). All benchmarks were compiled and run under rustc 1.68.0-nightly. The generate_report.py script will output a report.txt file containing measurements in milliseconds across a wide variety of parameters. Note that running the entire suite can take a very long time, because of the combinatorial explosion of parameters, frequent recompilations, and the high sample count in the criterion config.
Expectations: We generally expect hybrid to outperform packed in most cases and for the difference between them to become more apparent as we increase the producer count. The following sections contain figures and descriptions for each testing platform.Overall, we can confirm that the packed layout performs worse across the board, getting generally incrementally worse with higher thread count. I found that for the M1 Pro and i5-9600k, the level of simultaneous cache line accesses is a crucial factor for overall throughput. This makes sense intuitively, because CPUs have more time to complete their cache transaction, while the remaining instructions continue to be executed in parallel.
However, on the server platforms I noticed some unusual behavior. Starting from >15 producers, we can actually see very good packed performance when the indices are highly contended. Even more confusing, once we add dummy instructions (thereby releasing pressure on the same cache line), the hybrid layout starts to significantly outperform packed. What is going on here? Why is false sharing becoming more apparent when we reduce cache contention? The likely cause is that these servers are configured as multi-socket and multi-NUMA, and that the specifics of CPU/socket interconnect (which can be intimidatingly complex) cause this behavior.
We have seen that false sharing due to suboptimal layout has a real, non-negligible impact on performance for our wait-free data structure (the quote mentioned in the beginning of this post rings true). It performs worse than our hybrid layout across all measured parameters, with the exception of the dual-thread, single-producer case. We also saw that the hybrid layout scales much better with the number of concurrent producers (which is one of the goals of a performant MPSC queue).
However, while all measurements lean in favor of hybrid, the concrete comparative advantage heavily depends on the CPU architecture, hardware config and cache line contention. One surprising result on the server platforms is that by increasing the frequency of cache line accesses to the maximum, we actually reduce the relative penalty of false sharing, if done across NUMA nodes and multiple sockets.
- Sorin, Daniel J., Mark D. Hill, and David A. Wood. "A primer on memory consistency and cache coherence." Synthesis lectures on computer architecture 6.3 (2011): 1-212. [PDF]
- Hennessy, John L., and David A. Patterson. Computer architecture: a quantitative approach. Elsevier, 2011. [PDF]
- David, Tudor, Rachid Guerraoui, and Vasileios Trigonakis. "Everything you always wanted to know about synchronization but were afraid to ask." Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 2013. [PDF]
- Liu, Tongping, and Emery D. Berger. "Sheriff: precise detection and automatic mitigation of false sharing." Proceedings of the 2011 ACM international conference on Object oriented programming systems languages and applications. 2011.